本篇會淺淺地說說在設計Schema時就要考慮到笛卡兒乘績, 而要在選擇關係屬性要注意的地方.
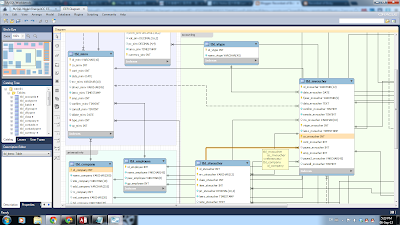
這圖就更清楚的顯示了, 資料表 (Table, 即頂端是藍色那些方塊) 間的關係, 這種關係是建立在不同資料表中的資料欄 (Field) 的關聯. 在上圖中以橙色所標示的關係是一種"一對多(One to Many)" 的關係. 左手邊的資料表 <tbl_company> 是用來記錄主公司的資料, 而另一邊的資料表 <tbl_mvoucher> 則是用記錄所有傳票的主要資料. 其中關聯的資料欄分別是 <tbl_company> 的 <<id_company INT>> 及 <tbl_mvoucher> 的 <<co_mvoucher INT>>, 而該關聯的性質是一對多. 形象化一點說明: 在這個關係中, 主公司的編號 (ID) 在 <tbl_company> 只會出現一次, 但是在 <tbl_mvoucher> 則可以出現無數次. 情況就如同, 一間公司可以有無數多張傳票 (Voucher) .
何謂一對多, 就是指一筆特定資料在資料表甲只會出現一次, 而在資料表乙則可以出現無數次. 而關聯性質不是只有一對多, 它還可以設定為"一對一 (One to One)" , "多對多 (Many to Many)" 及"多對一 (Many to One)". 直覺上"多對多"這種關聯性最有彈性, 但是當你使用查詢 (Query) 去組合兩個有多對多關聯的資料表時, 它卻會引出一個資料性夢魘: 笛卡兒乘績 (Cartesian Product). 當然, 你有可能為的就是要得到這樣的結果, 但是在簿記或會計之中, 笛卡兒乘績的用處應該不大.
既然公司的編號只出現一次, 那為什麼不把公司資料直接放在 <tbl_mvoucher>? 這是因為遵從了資料庫正規化 (Database Normalization) , 亦節省了資料庫在硬盤(Hard Drive) 及記憶體 (RAM) 上所佔據的位元空間從而縮短系統反應時間(Response Time). 說了這麼多, 那<<id_company INT>> 及 <<co_mvoucher INT>> 中的 "INT" 是什麼呢? 這個 "INT" 指的是資料的形態. 這是未來會講及的.
http://bickyacc.blogspot.com/2013/09/schema.html
 bickyacc
bickyacc


 iThome鐵人賽
iThome鐵人賽